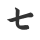



对比下 html上的数据 (部分截图-初始阶段)

输出结果(部分截图-结束阶段)

对比下 html上的数据 (部分截图-结束阶段)

好了, 这样的html数据采集就完成了. :)
当然这里只是抓取了一个页面的内容,如果感兴趣 想抓去更多的页面内容, 你可以分析下该链接后的联盟名, 例如 league=EngPrem
通过改变league名来获取所有联盟的比赛数据; 你也可以简单写个数组来装载所有的球队名称;
当然还有更智能的方法, 写个采集数据的方法从http://www.footballresults.org/allleagues.php 页面源代码里获取所有联盟的名字(如下图).

然后来附加到 "http://www.footballresults.org/league.php?all=1&league=" 链接后面 来补齐链接, 进而循环读取各个联盟比赛页面的内容.
Comments NOTHING